Linear Algebra as the Operating Substrate of Large Language Models

From Mathematical Foundations to Industrial-Scale AI SystemsWith an Applied Systems Perspective from Quantum Atomics by Quantum Tiger
Abstract
Large Language Models (LLMs) are often described in anthropomorphic terms, reasoning, understanding, creativity—yet their functional reality is far more precise. At scale, LLMs are deterministic systems executing vast sequences of linear algebraic operations under probabilistic optimization. This paper argues that linear algebra is not merely a mathematical prerequisite for LLMs but their operating substrate. Every stage of the LLM lifecycle, representation, training, inference, scaling, optimization, and deployment, reduces to transformations in high-dimensional vector spaces.
Building on this foundation, the paper introduces a systems-level perspective aligned with Quantum Atomics, the AI infrastructure operating layer developed by Quantum Tiger, demonstrating how linear algebra transitions from theory into production-grade, sovereign, and cost-controlled AI systems. The work aims to bridge mathematical rigor with industrial reality, especially for emerging enterprises and institutions operating outside hyperscaler dominance.
1. Introduction
The modern discourse around artificial intelligence often prioritizes emergent behavior while under-examining foundational structure. In the case of LLMs, this imbalance obscures a central truth: language models do not manipulate symbols or meanings in a classical sense. They operate entirely within vector spaces governed by linear transformations, optimization dynamics, and numerical stability constraints.
This paper reframes LLMs as linear algebraic engines with statistical supervision, rather than cognitive systems. Such a reframing is not academic pedantry; it has direct consequences for how models are designed, scaled, optimized, secured, and governed.
The argument proceeds in three layers:
- Linear algebra as the mathematical core of LLMs
- Linear algebra as the computational bottleneck and scaling constraint
- Linear algebra as the design language for AI operating systems such as Quantum Atomics
2. From Tokens to Vector Spaces
2.1 Language as Geometry
LLMs never encounter words, grammar, or meaning. They encounter vectors. Each token is mapped into a dense, continuous vector space where proximity encodes statistical co-occurrence rather than semantic intent. The embedding layer performs a lookup operation that places tokens into a shared coordinate system, allowing algebraic operations to approximate linguistic relationships.
Formally, an embedding matrix maps discrete indices into ℝⁿ. The resulting vectors form the foundational state upon which all downstream transformations operate.
Meaning, in this paradigm, is geometric:
- Similarity is distance
- Analogy is vector offset
- Context is subspace projection
This transformation from discrete language to continuous geometry is the first irreversible commitment to linear algebra in LLMs.
3. Neural Networks as Linear Transformation Chains
3.1 The Linear Core of Non-Linear Systems
Despite their name, neural networks are overwhelmingly linear systems with sparse non-linear interruptions. Each layer performs affine transformations followed by element-wise non-linearities.
The computational dominance lies in matrix multiplication. In large models, over 95% of compute time is consumed by dense linear algebra kernels. Non-linear activations serve primarily to preserve expressive capacity, not computational weight.
From a systems perspective, an LLM is a deeply layered composition of linear operators whose numerical properties dictate:
- Stability
- Convergence
- Throughput
- Hardware efficiency
This explains why architectural improvements often target matrix shapes, sparsity patterns, and memory layouts rather than algorithmic novelty.
4. Attention Mechanisms as Structured Linear Algebra
4.1 Self-Attention Without Metaphor
Self-attention is frequently described using cognitive metaphors. In practice, it is a structured sequence of matrix operations:
- Linear projection of inputs into query, key, and value matrices
- Dot-product similarity computation
- Normalization via softmax
- Weighted aggregation through matrix multiplication
Each step is a textbook linear algebra operation applied at extreme scale. Attention does not “focus”; it reweights vector influence across a token dimension.
The success of transformers lies in how efficiently they allow information flow across sequence dimensions using linear algebra rather than recurrence.
5. Optimization and Training as Vector Field Navigation
5.1 Gradient Descent in High-Dimensional Spaces
Training an LLM is equivalent to navigating a loss surface defined over billions of dimensions. Gradients, Jacobians, and higher-order derivatives determine the trajectory through this space.
Linear algebra governs:
- Gradient propagation
- Numerical conditioning
- Eigenvalue spectra of weight matrices
- Stability under learning rate schedules
Pathologies such as vanishing or exploding gradients are not abstract failures; they are consequences of poorly conditioned linear transformations.
6. Scaling Laws and the Geometry of Compute
6.1 Why Bigger Models Are Linear Algebra Problems
Scaling an LLM increases:
- Matrix dimensions
- Memory bandwidth requirements
- Communication overhead between partitions
As model size grows, the dominant constraints shift from algorithmic to algebraic:
- Matrix partitioning strategies
- Low-rank approximations
- Precision trade-offs
Techniques such as quantization, pruning, and LoRA are fundamentally matrix compression and factorization strategies. Their success depends on preserving geometric structure while reducing dimensionality.
7. Inference, Retrieval, and Vector Search
7.1 Reasoning as Nearest-Neighbor Geometry
During inference, LLMs repeatedly compute similarity between the current state vector and learned parameter spaces. Retrieval-augmented generation extends this by performing approximate nearest-neighbor search in embedding space.
What appears as “reasoned response selection” is, in practice, ranking vectors by distance under constrained latency.
This framing reveals why retrieval quality, embedding alignment, and vector database design materially affect output reliability.
8. From Mathematics to Systems: The Role of AI Operating Layers
8.1 Why Infrastructure Determines Capability
The transition from model theory to deployed intelligence introduces constraints absent from academic settings:
- Data sovereignty
- Latency guarantees
- Cost ceilings
- Regulatory compliance
These constraints are not solved at the model level. They are solved at the operating system level, where linear algebra meets hardware orchestration.
9. Quantum Atomics: A Linear Algebra–Native AI Operating Layer
9.1 Architectural Philosophy
Quantum Atomics, developed by Quantum Tiger, is designed around the premise that AI systems are linear algebra workloads first and application workloads second.
Rather than treating models as monolithic artifacts, Quantum Atomics decomposes AI workloads into:
- Atomic linear operations
- Modular inference and training pipelines
- Orchestrated compute graphs optimized for locality and sovereignty
This design aligns infrastructure decisions directly with the mathematical structure of LLMs.
10. On-Premise and Sovereign AI
10.1 Reclaiming Control of Vector Computation
In many sectors, exporting vectors is equivalent to exporting sensitive information. Embeddings encode behavioral, operational, and institutional signals even when raw data is absent.
Quantum Atomics addresses this by enabling:
- On-premise execution of vector workloads
- Controlled lifecycle management of embeddings
- Isolation of linear algebra kernels from external dependency chains
This is particularly relevant for SMEs, research institutions, and regulated industries where hyperscaler economics and governance models are misaligned.
11. Performance, Cost, and Linear Algebra Efficiency\
11.1 The Economics of Matrix Operations
AI cost structures reduce to:
- FLOPs per operation
- Memory movement per matrix
- Precision per multiply-accumulate
Quantum Atomics optimizes these parameters at the orchestration layer, allowing institutions to trade off precision, throughput, and latency without retraining foundation models.
This reframes AI deployment from capital-intensive experimentation to predictable infrastructure planning.
12. Implications for AI Strategy
Understanding LLMs through linear algebra yields several strategic insights:
- Model capability is bounded by numerical stability
- Infrastructure choice shapes reasoning fidelity
- Sovereignty depends on control of vector spaces
- Optimization beats brute-force scaling
Organizations that internalize these principles will out-execute those chasing parameter counts alone.
12.A. Systems Architecture of Quantum Atomics
A Linear Algebra–Native AI Operating Layer
12.1A Design Objective
Quantum Atomics, developed by Quantum Tiger, is designed around a single systems premise: LLMs are linear algebra workloads whose performance, security, and cost characteristics are determined more by orchestration than by model choice.
Rather than positioning itself as a model, Quantum Atomics functions as an AI operating layer that sits between hardware, foundation models, and enterprise applications, optimizing the execution of vector-heavy workloads under real-world constraints.
12.2A High-Level System Overview
At a macro level, Quantum Atomics decomposes AI systems into five tightly coupled layers:
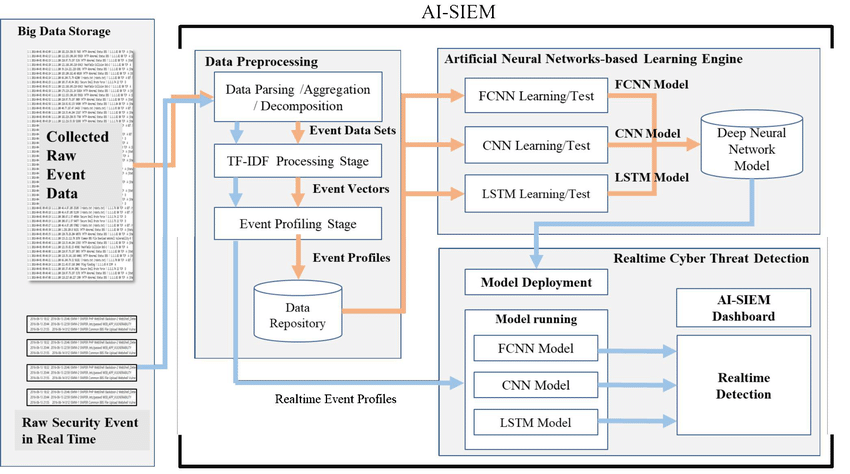
Layer 1: Compute Substrate
- CPU, GPU, or accelerator-agnostic
- Optimized for dense matrix multiplication and memory locality
- Supports mixed precision execution
Layer 2: Linear Algebra Kernel Layer
- Batched matrix multiplications
- Attention kernels
- Embedding generation and similarity computation This layer is where the majority of compute cycles are consumed and optimized.
Layer 3: Atomics Orchestration Layer
- Breaks AI workloads into atomic linear operations
- Schedules execution based on memory, latency, and cost constraints
- Manages parallelism and data movement explicitly
Layer 4: Model & Workflow Layer
- Hosts foundation models, fine-tuned variants, and adapters
- Enables LoRA, quantization, and low-rank techniques without model rewrites
- Separates model logic from execution logic
Layer 5: Application & Governance Layer
- Enterprise workflows, APIs, and dashboards
- Policy enforcement, auditability, and access control
- Integration with existing IT systems
12.3A Atomic Execution Philosophy
Traditional AI platforms treat models as indivisible black boxes. Quantum Atomics treats them as compositions of linear transformations.
Each inference or training step is decomposed into:
- Vector projections
- Matrix multiplications
- Normalization and scaling operations
- Controlled non-linear activations
This decomposition enables:
- Fine-grained scheduling
- Hardware-aware optimization
- Deterministic cost modeling
From a systems perspective, this converts AI execution from an opaque process into a governable computational graph.
12.4A Data Sovereignty and Vector Containment
A critical but often overlooked insight is that vectors are data.
Embeddings encode:
- Behavioral signals
- Institutional patterns
- Latent relationships
Quantum Atomics enforces sovereignty by:
- Keeping embedding generation and storage on-premise
- Preventing uncontrolled vector export
- Allowing organizations to define lifecycle policies for vector spaces
This is particularly relevant for regulated sectors and emerging enterprises where data export creates asymmetric risk.
12.5A Performance Optimization Through Linear Algebra Awareness
Performance tuning in Quantum Atomics is guided by linear algebra constraints rather than application heuristics.
Key optimization dimensions include:
- Matrix shape alignment with hardware
- Precision selection based on error tolerance
- Memory reuse across attention heads
- Avoidance of unnecessary tensor materialization
These optimizations reduce:
- Inference latency
- Power consumption
- Total cost of ownership
Without sacrificing model capability.
12.6A Deployment Modalities
Quantum Atomics supports multiple deployment configurations while maintaining architectural consistency:
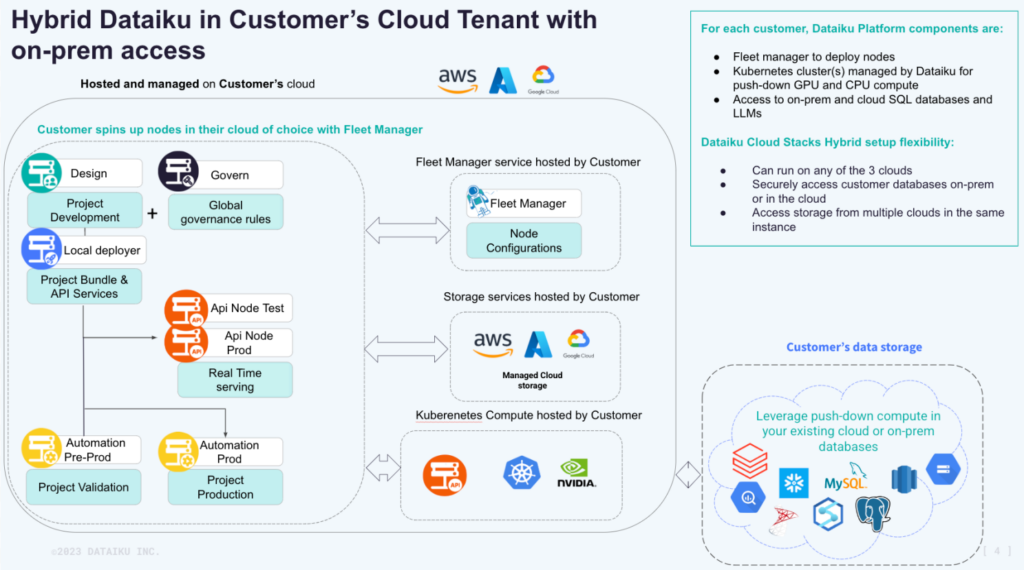
- Fully on-premise enterprise clusters
- Air-gapped institutional deployments
- Edge + core hybrid inference systems
In each case, the linear algebra execution model remains identical, ensuring portability without performance regression.
12.7A Why This Architecture Matters
From a systems standpoint, Quantum Atomics reframes AI deployment as an infrastructure problem rather than a model problem.
This yields three structural advantages:
- Predictable scaling grounded in compute geometry
- Cost control driven by algebraic efficiency
- Governance rooted in execution-level visibility
In effect, Quantum Atomics acts as a control plane for intelligence, translating mathematical structure into operational certainty.
12.8A Synthesis
Large Language Models scale because linear algebra scales. They fail operationally when systems ignore this reality.
Quantum Atomics aligns infrastructure design directly with the mathematical truth of LLMs, allowing institutions to deploy advanced AI systems without surrendering control, predictability, or sovereignty.
This architecture does not attempt to humanize machines. It accepts what they are—and builds accordingly.
End Note
Large Language Models are not mysterious cognitive entities. They are the largest linear algebra systems humanity has ever built, trained under probabilistic supervision and executed at industrial scale.
Recognizing this reality is not reductive; it is empowering. It allows founders, engineers, policymakers, and institutions to reason clearly about:
- What LLMs can and cannot do
- Where risk actually resides
- How control can be regained
Quantum Atomics by Quantum Tiger represents one practical instantiation of this philosophy: an AI operating layer that respects the mathematical truth of modern intelligence systems while translating it into deployable, sovereign infrastructure.
The future of AI will not be decided by abstractions. It will be decided by who controls the geometry.